「Perl の非同期I/Oモジュール POE を使って VPN-Warp relayagent を書いてみました」に 続いて、 同じく POE を使って VPN-Warp リレー サーバも書いてみました。 これで、オープンソースだけを使って VPN-Warp を実現することができます。
今までも、 BIGLOBE の VPN ワープのページから証明書を取得すれば、 月額 525円で VPN-Warp を試してみることはできたわけですが、 ちょっと試してみたい場合など、 有料であることがネックである感は否めませんでした。 特に、 常日頃からオープンソースを使いこなしている方々だと、 ちょっと使ってみたいだけなのにお金を払うのはねぇ、 と思ってしまうのではないでしょうか。 かくいう私も、 無料「お試し版」のサービスやソフトウェアに慣れきってしまっているので、 試しに使ってみようとする場合に、 それが有料だったりすると、 いきなり億劫になってしまう今日このごろだったりします (^^;)。
というわけで、 オープンソース版 VPN-Warp です。 使い方はあまりフレンドリーではありませんが、 なんたって全て公開してしまっているので、 興味あるかたは、 とことんいじってみてはいかがでしょうか。
relayagent.pl と同様、 今回公開する relayserver.pl も SSL 暗号化/復号の機能を含んでいません。 したがってリレー サーバへの https アクセスを stone などを 通して SSL 復号する必要があります。 例えば stone を
stone -z cert=cert.pem -z key=priv.pem \
localhost:12345 443/ssl &
などと実行しておき、 relayserver.pl を
relayserver.pl 12345
と実行します。これだけで 443番ポートはリレー サーバとして利用できます。 つまり、relayagent とブラウザからの https 接続を受付けると、 リレー サーバが両セッションを中継し 「ブラウザ → リレー サーバ → relayagent → Webサーバ」 という経路で通信できます。
リレー イントラ イントラ
ブラウザ ─────→ サーバ ←──── relayagent──→ Webサーバ
https 443番ポート 80番ポート
見かけは極めて tiny ですが、 通信プロトコルは本物(?)の VPN-Warp と互換性があるので、 「VPN-Warp relayagent フリー ダウンロード」から ダウンロードできる VPN-Warp relayagent を使うこともできます。
そもそも論で言えば、 リレー サーバの役目は単にデータを右から左へ渡すだけなので、 以下に示すようにその中核の部分は極めてシンプルです。 しかしながら、もちろんこれは KLab(株) で運用しているリレー サーバが単純であることを意味しません。 機能がシンプルでも、大量の同時接続 & 大量データを受付ける耐高負荷性能や、 機器の一部に故障が起きてもサービスが影響を受けない高可用性を実現するために、 様々な工夫を盛り込んでいます。
では、relayserver.pl の中身を順に見ていきましょう。
#!/usr/bin/perl
use POE qw(Component::Server::TCP Filter::Stream);
my $Port = shift;
my $PollID;
my $PollHeap;
my $PollBuf;
my $PollHeader;
my %SID;
my %Heap;
my %Buf;
my $NextSID = 0;
POE::Component::Server::TCP->new
(
Port => $Port,
ClientInput => sub {
my ($heap, $input, $id) = @_[HEAP, ARG0, ARG1];
if (defined $PollID && $id == $PollID) {
$PollHeap = $heap;
$PollBuf .= $input;
&doPoll;
} elsif (defined $SID{$id}) {
my $sid = $SID{$id};
$Heap{$sid} = $heap;
$Buf{$sid} .= $input;
&doSession($sid);
} elsif ($input =~ m@^GET /KLAB/poll @) {
if (defined $PollID) {
$heap->{client}->
put("HTTP/1.1 503 Service Unavailable\r\n\r\n");
$heap->{client}->shutdown_output;
return;
}
$PollID = $id;
$PollHeap = $heap;
$PollBuf = $input;
&doPoll;
} else {
$SID{$id} = $NextSID;
$NextSID = ($NextSID + 1) & 0xFFFF;
my $sid = $SID{$id};
$Heap{$sid} = $heap;
$Buf{$sid} = $input;
&doSession($sid);
}
},
ClientDisconnected => sub {
my $heap = $_[HEAP];
my $id = $heap->{client}->ID;
if (defined $PollID && $id == $PollID) {
undef $PollHeap;
undef $PollBuf;
undef $PollHeader;
undef $PollID;
} elsif (defined $SID{$id}) {
my $sid = $SID{$id};
undef $SID{$id};
undef $Heap{$sid};
undef $Buf{$sid};
}
},
ClientFilter => POE::Filter::Stream->new(),
);
POE::Kernel->run;
わずか 70行にも満たないコードですが、 リレー サーバの中核の部分は、ほとんどこれで全てです。 いかに POE (Perl Object Environment) の 記述性が高いか分かりますね。
私は常日頃から プログラマの生産性は、ピンとキリでは 3桁の違いがある と主張しています。 この主張をもう少し詳しく言うと、 その 3桁のうち、プログラマの腕に純粋に依存する部分は 2桁ほどの違いで、 残り 1桁ぶんは解決すべき問題に応じていかに最適な道具を使うかの違い、 ということになります。 最適な道具を使いこなせるもの腕のうち、 ということもできますね。
上記 70行にも満たないコードですが、 実は命令文としてみると、 わずかに 2 つの命令文であることが分かります。 すなわち、
POE::Component::Server::TCP->new(...中略...); POE::Kernel->run;
ですね。実質「POE::Component::Server::TCP->new(...中略...);」 だけと言ってもいいでしょう。 この命令文は、
POE::Component::Server::TCP->new
(
Port => $Port,
ClientInput => sub {
... クライアントから受信したデータの処理 ...
},
ClientDisconnected => sub {
... クライアントとの接続が切れたときの処理 ...
},
ClientFilter => POE::Filter::Stream->new(),
);
という構造になっています。 つまり、クライアントからデータが送られて来たときに呼び出されるルーチンと、 クライアントとの接続が切れたときに呼び出されるルーチンを指定しておけば、 あとは POE がうまくやってくれる、というわけです。簡単でしょう?
リレー サーバにとって「クライアント」というと、 ブラウザか relayagent になります。 クライアントからの TCP/IPセッション一本一本に対して POE が ID を割り振っていて、 この ID を見ればどの TCP/IPセッションで送られて来たデータか分かります。
「Perl の非同期I/Oモジュール POE を使って VPN-Warp relayagent を書いてみました」で 解説したように、 クライアントから送られて来た最初のデータが 「GET /KLAB/poll 」で始まっていれば、 そのクライアントは relayagent ですから、 以下のようにその ID ($id) を $PollID に代入しておきます。
elsif ($input =~ m@^GET /KLAB/poll @) {
if (defined $PollID) {
$heap->{client}->
put("HTTP/1.1 503 Service Unavailable\r\n\r\n");
$heap->{client}->shutdown_output;
return;
}
$PollID = $id;
$PollHeap = $heap;
$PollBuf = $input;
&doPoll;
}
同じ TCP/IPセッション (つまり $id == $PollID) で 続いて送られてきたデータは、 以下の部分で処理されます。
if (defined $PollID && $id == $PollID) {
$PollHeap = $heap;
$PollBuf .= $input;
&doPoll;
}
いずれの場合も、受信したデータはいったん $PollBuf に蓄えた上で、 「doPoll」ルーチンを呼び出します。
一方、ブラウザから送られてきたデータの場合は、 以下のようにセッションID ($SID{$id}) を順に割当てていきます。 「セッション」という単語が何度も出てきてややこしいのですが、 $id が POE が各 TCP/IPセッションに割当てた ID で、 各 TCP/IPセッションそれぞれに、 リレー サーバが 16bit の番号を割当てたのが VPN-Warp で言うところのセッションID ($sid = $SID{$id}) です。
else {
$SID{$id} = $NextSID;
$NextSID = ($NextSID + 1) & 0xFFFF;
my $sid = $SID{$id};
$Heap{$sid} = $heap;
$Buf{$sid} = $input;
&doSession($sid);
}
同じ TCP/IPセッション (つまりセッションID $sid が $SID{$id}) を通して 続いて送られてきたデータは、 以下の部分で処理されます。
elsif (defined $SID{$id}) {
my $sid = $SID{$id};
$Heap{$sid} = $heap;
$Buf{$sid} .= $input;
&doSession($sid);
}
いずれの場合も、受信したデータはいったん $Buf{$sid} に蓄えた上で、 「doSession」ルーチンを呼び出します。
つまり、relayagent から受信したデータは doPoll ルーチンで、 ブラウザから受信したデータは doSession ルーチンで、 それぞれ処理する、というわけです。 以下の図に示すように、 リレー サーバの役割は、 relayagent から受信した (ブロック化された) データを、 (ブロックを開梱しつつ) ブラウザへ送信し、 またブラウザから受信したデータを、 ブロック化して relayagent へ送ることですから、 doPoll および doSession が何をするためのルーチンか予想できますよね?
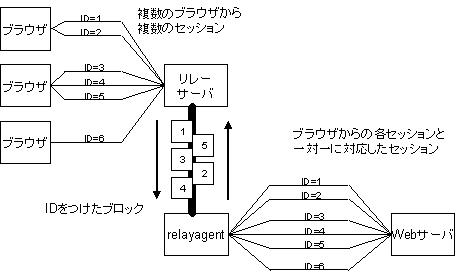
まず doPoll を見ていきましょう。
sub doPoll {
do {
if (! defined $PollHeader) {
if ($PollBuf =~ /\r\n\r\n/) {
$PollHeader = `;
$PollBuf = ';
$PollHeap->{client}->put("HTTP/1.1 200 OK\r\n\r\n");
}
}
return unless defined $PollHeader;
リクエストヘッダを全て読み込んでいない場合
(つまり $PollBuff に空行 \r\n\r\n が含まれていない場合)
は、ここで終わりです。
$PollBuf に受信データが追加されて、ふたたび doPoll が呼ばれるまで待ちます。
リクエストヘッダを全て読み込んだ場合は、 $PollBuf からリクエストヘッダ部分を削除した上で、 次に進みます。
my ($sid, $len, $data) = unpack("nna*", $PollBuf);
return unless defined $sid && defined $len && $len ne "";
ブロック全体を読み込めていない場合は、ここで終わりです。 $PollBuf に受信データが追加されて、ふたたび doPoll が呼ばれるまで待ちます。 「ブロック」というのは VPN-Warp 用語で、 relayagent とリレーサーバとの通信は、 基本的にこの「ブロック」を単位にして行ないます。 ブロックは次のような可変長のデータです。
┌───┬───┬───┬───┬───┬─≪─┬───┐
│セッションID│ データ長 │ 可変長データ │
└───┴───┴───┴───┴───┴─≫─┴───┘
2バイト 2バイト 「データ長」バイト
「セッションID」および「データ長」は、ビッグエンディアンです。 つまり上位バイトが先に来ます。 したがって、上記コードによって $sid, $len, $data にそれぞれ 「セッションID」「データ長」「可変長データ」が代入されます。
なお、データ長が 0 ないし負数の場合は、 「可変長データ」の部分は 0 バイトになります。 このような「可変長データ」がないブロックは、 コントロール用のブロックで、 EOF や Error などのイベントを伝えます。
if ($len > 32767) {
$len -= 65536;
$PollBuf = $data;
if ($len == -1) {
&doShutdown($sid);
}
}
$len == -1 のときは、Error を伝えるコントロール ブロックなので、 「doShutdown」ルーチンを呼び出しています。
elsif ($len > 0) {
return unless defined $data && length($data) >= $len;
($data, $PollBuf) = unpack "a${len}a*", $data;
if (defined $Heap{$sid}) {
$Heap{$sid}->{client}->put($data);
}
}
$len > 0 のときは、 $sid で示されるブラウザに対して $data を送信します。 $len == 0 のときは、 EOF を伝えるコントロール ブロックなので、 「doShutdown」ルーチンを呼び出しています。
else { # len == 0
$PollBuf = $data;
&doShutdown($sid);
}
} while ($PollBuf ne "");
}
以上を、$PollBuf が空になるまで続けます。
doShutdown はブラウザとの TCP/IPセッションを shutdown するためのルーチンです。
sub doShutdown {
my ($sid) = @_;
if (defined $Heap{$sid}) {
$Heap{$sid}->{client}->shutdown_input;
}
}
次に doSession です。
sub doSession {
my ($sid) = @_;
if (defined $PollHeap) {
my $req = $Buf{$sid};
$Buf{$sid} = "";
for my $block (unpack "(a2048)*", $req) {
$PollHeap->{client}->
put(pack("nna*", $sid, length($block), $block));
}
}
}
ブラウザから送られてきたデータを、 2048 バイトずつ区切って「セッションID」「データ長」を 前につけることによってブロック化して、 relayagent に送信しています。
オリジナルの VPN-Warp を使ったことがある方は既にお気付きかも知れませんが、 上記 relayserver.pl は説明を簡単にするために機能をいくつか省いています。 例えば、オリジナルのリレー サーバは、 接続する際はクライアント認証が必須で、 同じクライアント証明書を提示した relayagent とブラウザを 結び付ける機能があるのですが、 上記 relayserver.pl はクライアント認証を行なわないので、 任意のブラウザから接続可能ですし、 同時接続が可能な relayagent は一つだけです。
腕に覚えのあるかたは、 オリジナルの VPN-Warp と同等の機能を実現するには どのような修正を加えればよいか、 考えてみてはいかがでしょうか? そして、 こういうことを考えることが好きなかた、 「いっしょにDSASつくりませんか?」