国内に (自宅以外で)
IPv6 が使えるサーバが欲しかったので、
ServersMan@VPS を使ってみた。
ServersMan@VPS は仮想化プラットフォームが
OpenVZ
なので今まで敬遠していたのだが、
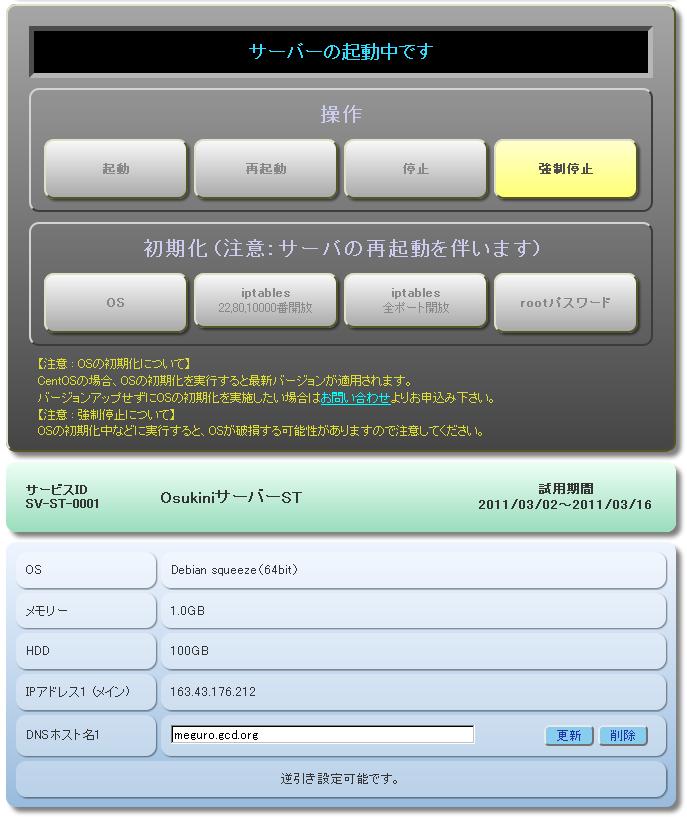
Osukini サーバ
(Xen) も、
さくらの VPS
(KVM) も、
いまのところネイティブな IPv6 はサポートしていない
(さくらの IPv6 は 6rd)
ので、
やむなく契約してみた次第。
Xen や KVM などの完全仮想化と異なり、
OpenVZ はホストOS のカーネルがゲスト OS のカーネルとしても使われる。
つまり VPS (Virtual Private Server)
サービスのユーザが別のカーネルを立ち上げることができない
(ServersMan@VPS Perfect は完全仮想化だが月額
3150円と高いのでここでは考えない)。
OS は CentOS, Debian, ubuntu から選ぶことになる。
しかしながら、
私が個人的に管理しているサーバは、
全て OS を独自の
「my distribution」
(便宜上ここでは GCD OS と呼ぶ)
に統一していて、
全サーバでディスクの内容を同期させている。
つまりある特定のサーバ固有の設定情報も、
全サーバが共有している。
共有していないのは各サーバのホスト名と、
秘密鍵などごく一部の情報だけ。
だからサーバが壊れた場合も、
新しいマシンを用意して他のサーバからディスク内容を丸ごとコピーするだけで済む。
私個人で管理しているサーバ (もちろん会社で運用しているサーバは除く) は、
仮想環境も含めると 20台ほどになるので、
異なる OS はできれば管理したくない。
ServersMan@VPS で提供されるカーネルを使うのは
(OpenVZ の仕組み上) 仕方がないとして、
ディスクの内容は GCD OS と入れ替えることにした。
稼働中のサーバをいじるとき重要なのが、
トラブった時に
「元に戻せるか?」
ということ。
元に戻せるなら多少の失敗を恐れることはない。
ほとんどの VPS サービスは、
最悪の事態に陥っても初期化すれば元通りになるので、
操作をミスっても一からやり直せばいいのだが、
OS を入れ替えようとする場合は
(当然) 新しい OS 一式を送り込む必要があり、
初期化するとこれが消えてしまうので再度転送する羽目になる。
GCD OS は最小セットで 7GB 近くあるので、
何度も転送を繰り返したりすると
VPS サービスの契約ネットワーク帯域を使いきってしまう。
幸い、
ServersMan@VPS に帯域制限は無いが、
一日に 何十GB も転送していたら、
きっと管理者に睨まれるはず。
そこで、
どんなに失敗しても、
再起動すれば ssh でログインできる状態に戻るような
OS 入れ替え手順を考えてみた。
ssh でログインできさえすれば後は何とでも修復できる。
逆に言うと ServersMan@VPS のようなコンソールが提供されない
VPS サービスでは ssh でログインできなくなると万事休す、
残された復旧手段は初期化しかない。
まず ServersMan@VPS Standard プランを契約 (月額 980円) して、
Ubuntu(64bit) の最小構成 (シンプルセット) を選択。
ssh でログインして
netstat でソケットを開いているデーモンを調べ、
片っ端から dpkg --purge (アンインストール) する。
もちろん sshd (ssh サーバ) だけは purge してはいけない。
syslog や cron などフツーは決して purge しないデーモンも遠慮無く purge する。
ps したとき sshd のプロセスのみが表示されるような状態になるまで
purge しまくる。
で、
一通り purge し終わったら念のため再起動してみる。
もしここで ssh でログインできなくなってしまっていたら、
初期化して振出しに戻る。
この時、
sshd が 22番ポートで listen している場合は、
GCD OS が起動する sshd と衝突するので、
22番ポート以外に変えておく。
幸い ServersMan@VPS の場合は sshd が初めから 3843番ポートで
listen する設定になっていた (なぜ?) ので、
そのままにしておく。
次に、
デーモン類以外のパッケージも、
残しておくとディスクの肥やしになるだけなので、
できるだけ purge する。
とはいっても、
多くのパッケージが数MB 以下で容量的には誤差の範囲なので、
無理に purge して再起不能状態に陥るリスクを冒すより、
ディスクの肥やしにしておいた方がマシ。
で、
一通り purge し終わったら念のため再起動してみる。
もしここで ssh でログインできなかったら、
初期化して振出しに戻る。
こうして
netstat -nap しても ps axf しても
sshd 以外のプロセスが一切残っていない状態になったら、
いよいよ GCD OS 一式を送り込む。
senri:/ # mirror -v -r /usr/local/gcd -e 'ssh -p 3843' \
'core64[183.181.54.38]' > /tmp/serversman &
mirror というのはサーバ間で GCD OS の同期を行なうためのスクリプト。
64bit (x86_64) の最小セットをコピーするために引数として
「core64」
を指定した。
このスクリプトは、
同期すべきファイルのリストを作成して
rsync を呼び出す。
「-e 'ssh -p 3843'」
オプションは、
そのまま rsync に渡される。
このコマンド列で GCD OS 最小セット約 7GB が
VPS の /usr/local/gcd ディレクトリ以下へ丸ごとコピーされる。
7GB の転送にどのくらいかかるかと思っていたら、
わずか 10分弱で終わってしまった。
100Mbps 以上の帯域ということになる。
結構すごい。
ホスト名を chiyoda.gcd.org に設定し、
このサーバ専用の秘密鍵を作成すれば GCD OS のインストールが完了。
あとは、
/usr/local/gcd 以下へ chroot して GCD OS を起動するだけ。
次のような GCD OS 起動スクリプト /etc/init.d/chroot を書いてみた。
#!/bin/sh
root=`echo $0 | sed -e 's@/etc/init.d/chroot$@@'`
if [ ! -d $root ]; then
echo "Can't find root: $root"
exit 1
fi
mount -obind /lib/modules $root/boot/lib/modules
chroot $root sh <<EOF
mount -a
svscanboot &
/etc/rc.d/rc.M
EOF
このスクリプトも GCD OS 一式をコピーするときに
/usr/local/gcd/etc/init.d/chroot へコピーされる。
で、/usr/local/gcd/etc/init.d/chroot を、
とりあえず手動で実行。
手動で実行するところがミソで、
もしこのスクリプトにバグがあって異常事態に陥っても、
再起動すれば元に戻る。
上記 /usr/local/gcd/etc/init.d/chroot は、
chroot /usr/local/gcd sh を実行して、
chroot 環境下で
svscanboot と
/etc/rc.d/rc.M を実行する。
svscanboot は
daemontools の起動スクリプト。
GCD OS のほとんどのデーモン類は daemontools の管理下で起動される。
一方 /etc/rc.d/rc.M は、
GCD OS のブートスクリプトで、
ファイアウォールなどネットワークまわりの設定や、
個々のサーバ特有の設定、
および一部のデーモン類の起動を行なう。
普通の Linux OS だと init から直接起動されるデーモンもあるが、
GCD OS の場合 init が起動するのは
/etc/rc.d/rc.S と /etc/rc.d/rc.M および svscanboot だけ。
/etc/rc.d/rc.S は、
OpenVZ 環境下では不要な処理ばかりなので実行する必要はない。
こうして chroot 環境下で GCD OS が起動したら、
chroot /usr/local/gcd sh などと実行して GCD OS 環境へ入ることができる。
各種設定が正しく機能しているか、
デーモン類が正しく動いているか確認する。
ServersMan@VPS で使われているカーネルが、
2.6.18-194.3.1.el5.028stab069.6 と、
かなり古い (2.6.18 などという 5年も昔のカーネルを使い続けないでほしい > RHEL)
ので、
GCD OS をきちんと動かすには問題があった。
特に困ったのが、
iptables の owner モジュールが使えない点:
chiyoda:/ # uname -rv
2.6.18-194.3.1.el5.028stab069.6 #1 SMP Wed May 26 18:31:05 MSD 2010
chiyoda:/ # iptables -t nat -j REDIRECT -p udp --dport 53 --to-port 2053 \
-A dnscache.lo -s 127.0.0.1 -d 127.0.0.1 -m owner ! --uid-owner Gdnscache
iptables: No chain/target/match by that name.
このエラーは、
カーネルに
CONFIG_NETFILTER_XT_MATCH_OWNER の設定がないのが原因。
NETFILTER_XT_MATCH_OWNER が導入されたのは 2.6.25 以降なので、
そもそも元から 2.6.18 には存在しない。
なぜ --uid-owner が必要かと言えば、
GCD OS では tinydns と dnscache を、
同じ IP アドレスで動かすことが基本になっているから。
つまり、
通常の名前解決に 127.0.0.1 の dnscache を利用するのだが、
dnscache (Gdnscache 権限で動作) が 127.0.0.1 に問合わせる時に限り
mydns が返事をするようにしたい。
仕方がないので、
iptables に --uid-owner を指定してエラーになる場合は、
--uid-owner 抜きで iptables を再実行するように修正した:
nsredirect="-t nat -j REDIRECT --dport 53 --to-port $PORT"
chain=dnscache.lo
iptables -t nat -N $chain 2>/dev/null || iptables -t nat -F $chain
nsinner="$nsredirect -A $chain -s 127.0.0.1 -d 127.0.0.1 \
-m owner ! --uid-owner Gdnscache"
iptables -p udp $nsinner
if [ $? -ne 0 ]; then
nsinner="$nsredirect -A $chain -s 127.0.0.1 -d 127.0.0.1"
iptables -p udp $nsinner
fi
iptables -p tcp $nsinner
このような修正を、
chiyoda.gcd.org だけでなく、
GCD OS をインストールしている全サーバで一斉に行なう点がミソ。
サーバごとにファイルの内容が微妙に異なっていたりしたら、
GCD OS を使う意味がない。
当然、
--uid-owner 抜きで iptables を実行した場合は、
dnscache が 127.0.0.1 の mydns に問合わせをすることができないが、
127.0.0.1 以外、
つまり 183.181.54.38 あるいは 2001:2e8:634:0:2:1:0:2a ならば
mydns に問合わせることができるので問題無い。
じゃ、
なんのために、
わざわざ --uid-owner を使って 127.0.0.1 の
mydns に問合わせられるようになっているかというと、
127.0.0.1 以外の IP アドレスが動的に変わるサーバ (ノートPC など)
も想定しているから。
GCD OS は VirtualBox や Xen などの完全仮想化環境だけでなく、
coLinux や今回の OpenVZ など、
仮想化環境としてはやや異質なものもサポートしている。
以上のような細かい修正を行なっていって、
GCD OS が問題無く立ち上がるようになったら、
/usr/local/gcd/etc/init.d/chroot の呼び出しを
(ubuntu の) /etc/rc.local に追加して、
VPS の起動時に自動的に GCD OS が起動されるようにする。
GCD OS が正しく立ち上がれば、
外部から 22番ポートに対して ssh ログインして GCD OS が使える。
22番ポートでログインできることが確認できたら、
3843番ポートの sshd は止めてもよい。
chroot 環境からはいつでも脱出できるので、
3843番ポートを止めても本来の
(chroot する前の) ubuntu 環境にアクセスすることが可能:
senri:~ # ssh chiyoda.gcd.org
Enter passphrase for key '/root/.ssh/id_rsa':
Last login: Sat Jul 30 09:14:54 2011 from 2409:82:5fff:0:5542:d84e:971a:9656
Linux 2.6.18-194.3.1.el5.028stab069.6.
chiyoda:~ # ls -F / ↓ GCD OS
bin@ dev/ ftp/ lib/ proc/ run/ sys/ usr/
boot/ etc/ home/ lib64@ root/ sbin@ tmp/ var/
chiyoda:/ # chroot_escape /bin/bash ← chroot から脱出
groups: cannot find name for group ID 11
groups: cannot find name for group ID 14
root@chiyoda:/# ls -F --color=never ↓ ubuntu
aquota.group@ boot/ fastboot lib32/ mnt/ sbin/ sys/ var/
aquota.user@ dev/ home/ lib64@ proc/ selinux/ tmp/
bin/ etc/ lib/ media/ root/ srv/ usr/
root@chiyoda:/# cat /etc/debian_version
squeeze/sid
root@chiyoda:/# lsb_release -r
Release: 10.10
root@chiyoda:/# exit
chiyoda:~ # ↓ GCD OS
「chroot_escape /bin/bash」
が、
chroot 環境から脱出するコマンド。
脱出して、
「本来の」
root 環境 (この例では ubuntu) 下で、
引数のコマンド
「/bin/bash」
を実行する。
この bash を使って ubuntu の操作ができて、
exit すると元の GCD OS へ戻る。
まるで chroot 下の GCD OS の方が 「主」 で、
本来の root が 「従」 のように見える ;-)。
なお、
chroot_escape コマンド実行時の
「groups: cannot find name for group ID 〜」
というエラーは、
GCD OS の /etc/group と ubuntu の /etc/group が異なるため。
つまり GCD OS の root は ID 11 と 14 のグループに属しているが、
ubuntu には ID が 11 と 14 のグループが存在しないため、
このようなエラーが表示される。
ここまでやるなら、
chroot といわず root に GCD OS をインストールしてしまえば?
という声が聞こえてきそうであるが、
ServersMan@VPS ではコンソールが利用できないため、
トラブったときのために何らかの
「バックドア」
は残しておきたい。
GCD OS がどのような状況に陥っても、
3843番ポートの sshd
(init から起動されるので kill しても再起動する)
にログインできれば、
ubuntu 環境で GCD OS の修復が可能。
というわけで一週間ほど ServersMan@VPS Standard プランを使っているが、
意外に (失礼!) 使えるので驚いた。
実は、
OpenVZ な 512MB ということであまり期待していなかった。
OpenVZ は swap を使えないので、
メモリ 512MB だと、
ちょっと重い処理をさせるだけですぐ OOM Killer が動き出すのだろうと思っていた。
ところが、
chiyoda:~ $ free
total used free shared buffers cached
Mem: 2097152 425020 1672132 0 0 0
-/+ buffers/cache: 425020 1672132
Swap: 0 0 0
512MB というのは実メモリ? の割当量のようで、
見かけ上は 2GB のメモリがある。
OpenVZ な VPS サービスによっては、
これをメモリ 2GB と言い張るところもあるんじゃないかと思うので、
ServersMan@VPS は良心的。
どのくらいのパフォーマンスなのか、
この日記 (WordPress を使用)
の処理時間を測ってみる。
senri.gcd.org から ApacheBench でアクセスすると:
senri:~ $ /usr/apache2/bin/ab -n 10 http://chiyoda.gcd.org/blog/
This is ApacheBench, Version 2.3 <$Revision: 655654 $>
...
Connection Times (ms)
min mean[+/-sd] median max
Connect: 6 7 0.3 7 7
Processing: 992 1116 94.1 1139 1259
Waiting: 305 403 78.3 380 561
Total: 998 1122 94.1 1146 1265
これを、
Linode Xen 512MB プラン
(fremont.gcd.org)
と比較する。
fremont.gcd.org は米国西海岸にある VPS なので、
同じく西海岸にある prgmr.gcd.org
から ApacheBench でアクセスすると:
prgmr:~ $ /usr/apache2/bin/ab -n 10 http://fremont.gcd.org/blog/
...
min mean[+/-sd] median max
Connect: 2 3 0.1 3 3
Processing: 996 1081 73.8 1084 1197
Waiting: 354 391 30.5 388 450
Total: 999 1084 73.8 1086 1200
両者は、
ほとんど同等のパフォーマンスであることが分かる。
Linode Xen 512MB プランは、
ディスク 20GB で月額 $19.95 (約 1600円)
なので、
ServersMan@VPS Standard プラン (ディスク 30GB, 月額 980円)
の方がコストパフォーマンスが良い。
もちろん、
ServersMan@VPS Standard には、
カーネルのバージョンが古すぎ、という問題点があるし、
メモリ 512MB を超える部分のパフォーマンスは、
ホストOS 側の負荷状況に左右されると思われるので、
単純に比較すべきではない。



 ハワイ唯一の公共交通機関
ハワイ唯一の公共交通機関